

目次
はじめに
Androidアプリエンジニアのカワニシです。
昨今、ChatGPTに代表されるようなAIを活用したサービスが次々とリリースされています。 技術ブログを見渡してもAIを活用したさまざま解説記事が出ており、自分も少し触ってみようと思いました。
そこで、今回はAI執事を作ろうと題して、夏休みの工作感覚で簡単なアプリを作成してみました。
内容をざっくり説明しますとChatGPT(OpenAI API)に耳と声を付けてあげましょうという内容です。
慣れないJSで書いたのでもろもろ汚い状態ではありますがご容赦ください。
喋った音声をChatGPTに伝えるには?
まずはChatGPTの耳となる処理を作っていきます。
ChatGPTのAPIの入力はテキスト形式のため、喋った音声をテキストに変換する必要があります。
そこで今回はブラウザの音声認識機能を使用します。
ブラウザの音声認識機能は端末や使用するブラウザによって違うので注意が必要です。 今回はMacのChromeで動作確認をしています。
上記を実行すると音声認識を待ち受け開始して、認識できたら ended(speakText)コールバック が呼ばれます。
認識後や無音状態が連続して自動で認識停止する場合がありますが、その場合でも再度認識をスタートさせているため無限に待受を続けます。
今回は実験的に実装しているため認識をストップする処理は入れていません。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
const startSpeechRecognition = async (ended) => { console.log("start SpeechRecognition"); let isSpeaking = false; const recognition = new webkitSpeechRecognition(); recognition.lang = "ja-JP"; recognition.onresult = (event) => { if (event.results.length > 0) { const speakText = event.results[0][0].transcript; console.log("recognized : " + speakText); isSpeaking = true; ended(speakText, function () { console.log("continue SpeechRecognition 1"); isSpeaking = false; if (recognition && !recognition.isRecording) { try { recognition.start(); } catch (error) { // ignore error } } }); } else { console.log("failed SpeechRecognition"); console.log("continue SpeechRecognition 2"); isSpeaking = false; if (recognition && !recognition.isRecording) { recognition.start(); } } }; if (recognition && !recognition.isRecording) { recognition.start(); } recognition.addEventListener("end", (event) => { if (isSpeaking) return; console.log("continue SpeechRecognition 3"); if (recognition && !recognition.isRecording) { recognition.start(); } }); }; |
– 上記のコードで音声認識したテキストを取得することができますが、認識精度はそれほど高くありません。
興味のある方はChatGPTのOpenAIが公開しているWhisper(https://openai.com/research/whisper) などに音声認識処理を置き換えてみてもいいでしょう。
Whisperですと使用する認識モデルにもよりますが、ブラウザのときよりかなり正確に認識をしてくれるようになります。
認識したテキストをChatGPTに渡して回答を取得するには?
次に音声認識したテキストをChatGPTに渡して回答を取得します。
OpenAIのAPI Keyの取得方法や課金設定はここでは解説しませんので、公式サイトなどで調べて設定しておいてください。
OPENAI_API_KEYに取得したAPI KeyをセットするとChatGPTから回答が取得できるようになります。
ChatGPTのAPIは基本有料なので無料枠を超えるようなら課金額には注意しましょう。
[OpenAI 使用量確認](https://platform.openai.com/account/usage) 無料枠でも結構使える印象です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
const loadAgentResponse = async (OPENAI_API_KEY, speakText) => { const openAiParams = { headers: { Authorization: `Bearer ${OPENAI_API_KEY}`, "Content-type": "application/json", }, method: "POST", body: JSON.stringify({ model: "gpt-3.5-turbo", temperature: 0.7, messages: [ { role: "user", content: speakText }, { role: "system", content: `あなたはAI執事として振る舞ってください` }, ], }), }; const OPENAI_URL = "https://api.openai.com/v1/chat/completions"; const response = await fetch(OPENAI_URL, openAiParams); const json = await response.json(); return json.choices[0].message.content; }; |
ChatGPTの回答を喋らせるには?
今回は音声合成にVOICEVOXを使用します。
VOICEVOXだとローカルのGPUを使った処理ができ高速です。
[VOICEVOX | 無料のテキスト読み上げソフトウェア](https://voicevox.hiroshiba.jp/)
VOICEVOXをインストールして起動しておくと、バックグラウンドでhttp://localhost:50021にWebAPIを提供するWebサーバーを立てています。
VOICEVOXにテキストを渡すと音声バイナリが返されるのでそれをブラウザで再生します。
発話内容のイントネーションなどを生成する audio_queryAPIと実際に音声を生成するsynthesisAPIを組み合わせて使います。
spekerにはVOICEVOXのキャラクターIDを指定します。
発話が完了するとendedコールバックが呼ばれます。
下記はテキストを渡して音声を生成してブラウザでその音声を再生するサンプルです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
const speakWithVoiceVox = async (speaker, text, ended) => { try { const response = await fetch( "http://localhost:50021/audio_query?text=" + encodeURI(text) + "&speaker=" + speaker, { method: "POST", headers: { "Content-Type": "application/json" }, } ); const query = await response.json(); const synthesis_response = await fetch( "http://localhost:50021/synthesis?speaker=" + speaker, { method: "POST", body: JSON.stringify(query), responseType: "arraybuffer", headers: { accept: "audio/wav", "Content-Type": "application/json", }, } ); const synthesis_response_buf = await synthesis_response.arrayBuffer(); const audioContext = new AudioContext(); const buffer = await audioContext.decodeAudioData(synthesis_response_buf); const source = audioContext.createBufferSource(); source.buffer = buffer; source.connect(audioContext.destination); source.start(); console.log(`speak: ${text}`); source.addEventListener("ended", ended); } catch (error) { console.error("speak Error:", error); ended(); } }; |
まとめ
後は上記を組み合わせて,喋れば答えてくれるAI執事さんができあがりです。
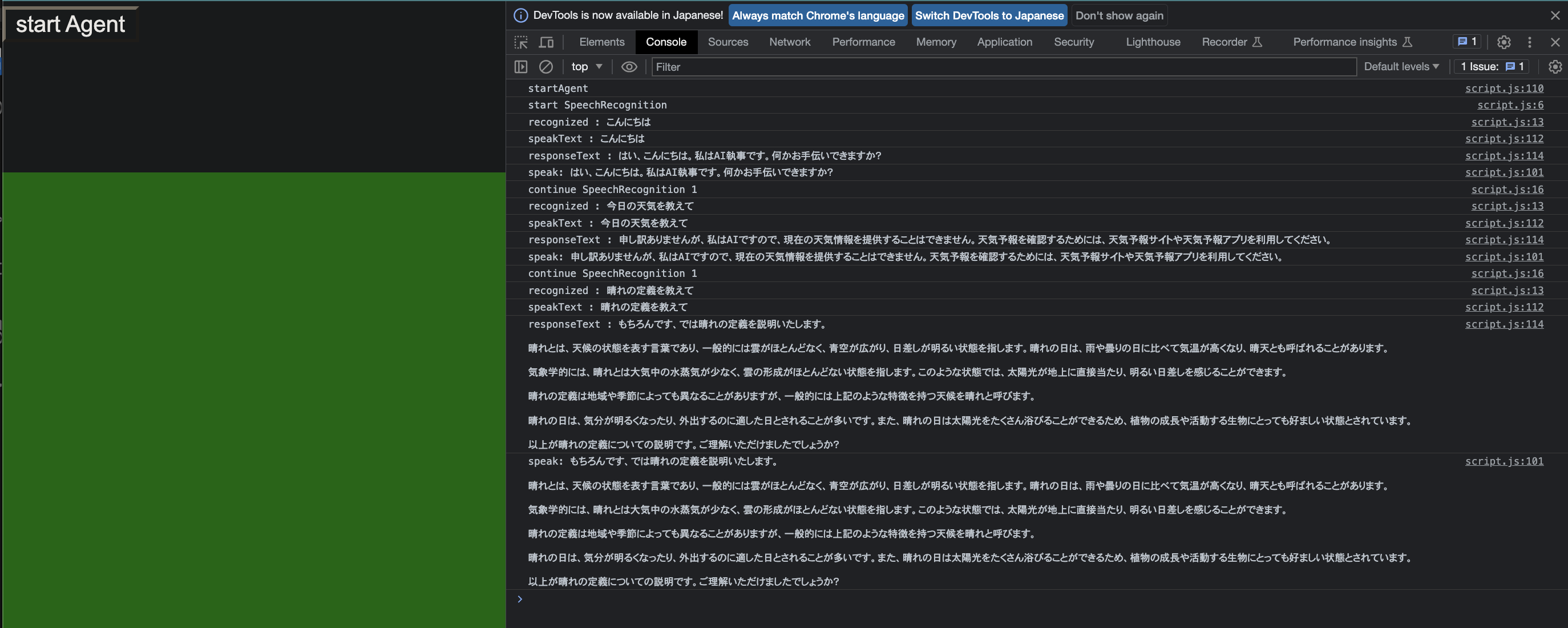
これくらいなら週末少しやるだけでも簡単に作れました。
すでにChatGPTから音声認識ができるiOSアプリなどが公開されていますが、 音声認識と音声合成の処理はテキスト形式のものであれば他にも応用ができますので、 自分なりに別のサービスと組み合わせて試してみてると面白いかもしれません。
今回は簡易的に実装してみましたが、 さらに実用的なものを作る場合は
・Whisperを使用して音声認識の精度をさらに上げる
・長い回答の場合は分割して音声合成することで発話可能になるまでの遅延をごまかしてみる
・過去の会話内容も含めてOpenAIで回答を生成する といったことをやってみるといいかもしれません。
今回作成したコードは全文はこちらになります。
index.html
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
<!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <title>Frame 1920x1080</title> </head> <body> <div id="system-container"> <button id="start-agent">start Agent</button> </div> <div id="container"></div> <script type="module" src="./js/script.js"></script> </body> </html> |
script.js
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 |
// use your own Open API key export const OPENAI_API_KEY = "hogehoge API Key"; const startSpeechRecognition = async (ended) => { console.log("start SpeechRecognition"); let isSpeaking = false; const recognition = new webkitSpeechRecognition(); recognition.lang = "ja-JP"; recognition.onresult = (event) => { if (event.results.length > 0) { const speakText = event.results[0][0].transcript; console.log("recognized : " + speakText); isSpeaking = true; ended(speakText, function () { console.log("continue SpeechRecognition 1"); isSpeaking = false; if (recognition && !recognition.isRecording) { try { recognition.start(); } catch (error) { // ignore error } } }); } else { console.log("failed SpeechRecognition"); console.log("continue SpeechRecognition 2"); isSpeaking = false; if (recognition && !recognition.isRecording) { recognition.start(); } } }; if (recognition && !recognition.isRecording) { recognition.start(); } recognition.addEventListener("end", (event) => { if (isSpeaking) return; console.log("continue SpeechRecognition 3"); if (recognition && !recognition.isRecording) { recognition.start(); } }); }; const loadAgentResponse = async (OPENAI_API_KEY, speakText) => { const openAiParams = { headers: { Authorization: `Bearer ${OPENAI_API_KEY}`, "Content-type": "application/json", }, method: "POST", body: JSON.stringify({ model: "gpt-3.5-turbo", temperature: 0.7, messages: [ { role: "user", content: speakText }, { role: "system", content: `あなたはAI執事として振る舞ってください` }, ], }), }; const OPENAI_URL = "https://api.openai.com/v1/chat/completions"; const response = await fetch(OPENAI_URL, openAiParams); const json = await response.json(); return json.choices[0].message.content; }; const speakWithVoiceVox = async (speaker, text, ended) => { try { const response = await fetch( "http://localhost:50021/audio_query?text=" + encodeURI(text) + "&speaker=" + speaker, { method: "POST", headers: { "Content-Type": "application/json" }, } ); const query = await response.json(); const synthesis_response = await fetch( "http://localhost:50021/synthesis?speaker=" + speaker, { method: "POST", body: JSON.stringify(query), responseType: "arraybuffer", headers: { accept: "audio/wav", "Content-Type": "application/json", }, } ); const synthesis_response_buf = await synthesis_response.arrayBuffer(); const audioContext = new AudioContext(); const buffer = await audioContext.decodeAudioData(synthesis_response_buf); const source = audioContext.createBufferSource(); source.buffer = buffer; source.connect(audioContext.destination); source.start(); console.log(`speak: ${text}`); source.addEventListener("ended", ended); } catch (error) { console.error("speak Error:", error); ended(); } }; const startAgent = async () => { console.log("startAgent"); startSpeechRecognition(async (speakText, ended) => { console.log("speakText : " + speakText); const responseText = await loadAgentResponse(OPENAI_API_KEY, speakText); console.log("responseText : " + responseText); speakWithVoiceVox(1, responseText, ended); }); }; window.onload = function () { const startAgentElement = document.getElementById("start-agent"); startAgentElement.addEventListener("click", startAgent, false); }; |
参考
[AITuber育成完全入門(冴えないAITuberの育て方)|みゆきP|note](https://note.com/hit_kam/n/n64162d96e3e9)
[API Reference – OpenAI API](https://platform.openai.com/docs/api-reference/making-requests)
[VOICEVOX | 無料のテキスト読み上げソフトウェア](https://voicevox.hiroshiba.jp/)
[slackのメッセージをVOICEVOXのAPIを使って読み上げてみるテスト | DevelopersIO](https://dev.classmethod.jp/articles/40f349d594a642f3669c67d9d10e927b12df839d1d48403e8e50fe9d9cea20bf/)
[ChatGPTにギルガメッシュ王の人格を与えるには?|深津 貴之 (fladdict)|note](https://note.com/fladdict/n/neff2e9d52224)
ソニックムーブは一緒に働くメンバーを募集しています
Wantedlyには具体的な業務内容のほかメンバーインタビューも掲載しております。ぜひご覧ください。












